分类与回归问题
机器学习要解决的问题,主要还是围绕的“分类与回归”两大问题来展开。
- 图像识别:大部分会归为分类任务
- 目标检测: 找到图片中的位置,同时找到类别,即属于分类问题与属于回归问题
分类问题还是回归问题的判断
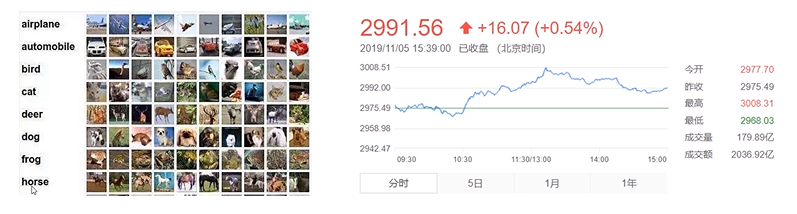
分类任务是指用离散的值来描述的任务,如上左图,一共有10分类别,对应有10维禹量。假如某分图片的10维向量为:[0.1,0.1,0.10.1,0,0,0,0.5,0.1,0] , 其中0.5的概率最大,而0.5在该向量中位于第8的位置,那说明该图像的分类为"dog"。 总之:我们预测10类别,对应有总和为1的10维向量,我们就称为该向量为10维向量,其中每个向量的索引值即为类别的编号。 同量,如果我们要预测1000个类别,则输入为1000维向量,同样索引位置即为类别编号, 总和为1。
与分类任务相对的则是回归任务,输出为连续值,而不是离散值,如上右图,是一个股票价格的预测、房价的预测、身高的预测等,解决连续值的预测。因此我们可以这么定义回归任务:如果我们网络或采用机器学习的模型最终输出的是一个连续值,那称之为回归任务。
机器学习构成元素
机器学习围绕 样本、模型、训练、测试、推理 这五个元素开展工作。
样本
样本是获取知识的依据(数据)。对于机器学习问题而言,并不是进行盲目的进行推理,一般是根据已知的内容来抽取出一个客观的规律,再根据规律进行推理与预测。这些规律就是从样本挖掘而出,对应的机器学习中的 学习
样本包括以下两样内容:
- 属性:描述样本本身的性质
- 标签:样本的类别,可以是离散和也可以是连续的
可以用y = f(x)函数来表示属性与样本之间的关系,其中x为属性,y为标签。标签是由属性归纳总结而来。
模型
有了样本(x,y) 之后,就可以用模型来将规律挖出,模型就对应y =f(x)函数中的f,即f为函数关系,通过挖掘样本属性之间的内在联系,来得到样本的标签。模型的公式:f(x) = wx + b
训练
学习这个模型的过程,就是所谓的训练过程。也就是求解w,b过程,其中w和b称为参数。
求解参数的方法很多,用PyTorch主要是用深度学习的方式来实现。即通过训练,能够求解出模型中的参数。
测试
通过训练,能够求解出模型中的参数。训练得到参数后,就可以对当前的模型进行测试与评估。我们通过机器学习的方法计算出的一组参数,我们认为这组参数是最优的,但到底有多好,是否还有其他方法求解出来的参数是否比之训练得到的模型参数最终预测结果会更好呢?这个时候我们会通过一套测试方法来完成。总之通过测试我们能够完成对模型性能的评估。
分类:ROC曲线
评价:PR曲线进行评价
PR 曲线是一种用于评估二分类模型性能的可视化工具。它以查准率为纵轴,召回率为横轴绘制曲线。
ROC曲线全称是"Receiver Operating Characteristic"曲线,被广泛用于评价分类器的性能。
推理
如果性能OK,,则就有了f(x)函数, 其中f为训练后的模型。现拿到一组样本,该样本只有属性没有标签,我们利于f(x)函数,对该样本进行推理,获取标签。利于学习所得的模型来获取样本标签的过程称为推理。
机器学习的泛化与优化
优化(optimization): 是指调节模型以在训练数据上得到最佳性能,即机器学习中的学习
泛化(generalization):是指训练好的模型在前所未见的数据上的性能好坏。
泛化能力:根据泛化能力强弱可以分为:
- 欠拟合: 模型过于简单,不能在训练集上获得足够低的误差
- 拟合: 测试误差与训练误差差距较小;
- 过拟合: 过分关注训练集细节,在训练集上表现良好,但不能泛化到新数据上
- 不收敛: 模型不是根据训练集训练得到的。



